

Mastering XML with Python (2): Doing (much) more with (much) less
Fear no more: using Python, even the most daunting obstacle in the way can become the way.

In the last post, we saw how to handle ODM-XML files using some Python libraries, making the process less daunting and simpler.
## Do you remember these libraries? ##
import requests
from lxml import etree
import pandas as pd
These libraries (especially pandas and lxml.etree) are designed to optimize the construction and manipulation of datasets contained in an XML document. However, we might encounter some obstacles along the way that were not addressed in the previous article. Here are a few:
The XML document is huge: Previously, we used a file that was small in size; we know that in real life, things might not always be like that. We might end up with a file that is 1GB or larger;
You don't need all the data contained in the file: To manipulate an XML document, libraries like
lxmlandElementTreeneed, by the nature of this type of file, to read and interpret an XML from start to finish. For reasons like the problem mentioned above, this costs time and memory, affecting the performance of your Python script.You don't have a robust machine available: The two problems above are much harder to solve when we have a more limited machine. Using platforms like Google Colab can be a workaround for this, but we can't always rely on this resource.
From this, you might think something like, "I'm back to square one; how am I going to manipulate this darn XML and get the data I need? Will I have to look for an alternative other than Python?"
The goal of this article is to show that it's not time to give up on Python yet. By changing a few things in the code, you will certainly have another chance to tackle the "monsters" of XML and finally extract the much-anticipated data and information.
Understanding the obstacle itself
To start, let's focus on some of the first lines of code we're using:
from lxml import etree
import requests
url = 'https://github.com/cdisc-org/DataExchange-ODM/raw/main/examples/Demographics_RACE/Demographics_RACE_check_all_that_apply.xml' #Fonte do arquivo .xml que estamos utilizando
response = requests.get(url) #HTTP Request
tree = response.content #The request content
This block of code, as seen above, does three things: 1) Stores a string of a GitHub URL; 2) Makes a request to this URL via requests to get its content; and 3) Stores the content of the request in a variable (i.e., the XML file from which we will extract data).
The next step is to transform the content of the tree variable into something that can be read and explored by lxml, using the XML function. Like this:
tree = etree.XML(tree, etree.XMLParser(remove_comments=True))
print(tree)
<Element {http://www.cdisc.org/ns/odm/v2.0}ODM at 0x145a22f7a80>
The process of parsing, which is done here by lxml.etree, involves transforming the content extracted from the GitHub URL into an ODM tree with all its elements. This allows us to fully explore the content of the entire XML document since the element tree will be in the computer's memory, ready to be used...
... and that's where the problem might be.
Understanding the size of the obstacle
As mentioned earlier, the example we're using can be considered small in various ways. Besides the size, we can assume that the ODM tree resulting from the parsing isn't very large either. Transferring the example to your computer and running the entire script, it's possible that the processing will be fast and won't take up much memory.
For more real-life scenarios, it's not always like this. From personal experience, I've had to deal with XML files that, once transformed into pandas DataFrames, had more than 8 million rows. To give you an idea, an Excel spreadsheet has a row limit of just over 1 million. A real "monster."
For the ODM tree to be used through an lxml parse, it needs to be completely "unpacked," requiring memory allocation not only for the root node (which can be seen in this case using the tree.tag attribute in lxml) but also for the child nodes, or children, of the entire structure. This allocation not only adds complexity but can also consume a lot of the computer's memory (an example of how all this would be distributed in memory is illustrated in the diagram below).
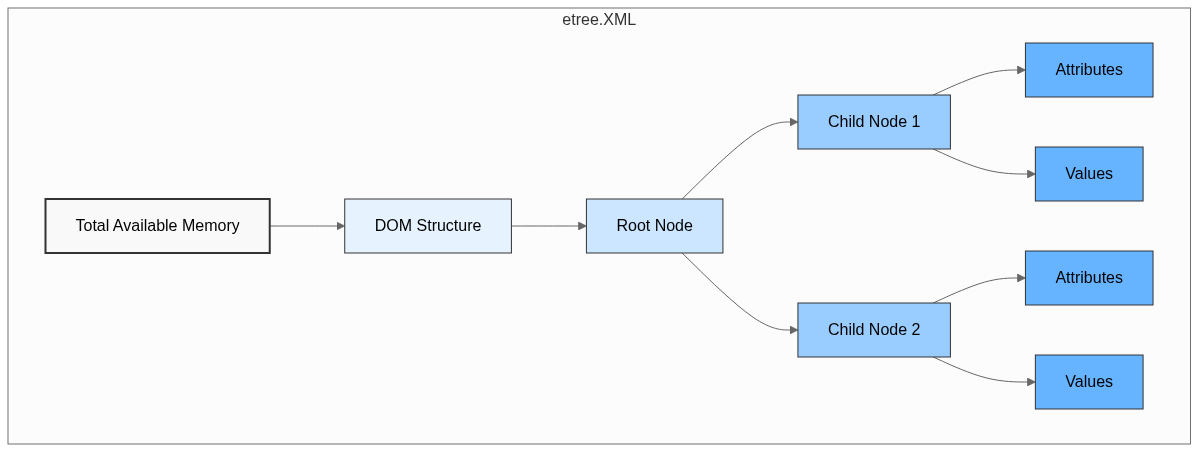
The obstacle in the way starts to become the way
The idea here is to open the XML's structural tree without storing it all in memory. Instead, we open the data temporarily, allowing us to read the data sequentially without processing the entire file. This approach is especially recommended when we don't need all the data contained in the XML file. To do this, we'll add another Python library to our "toolbox": io.
Check out the snippet below:
import requests
from lxml import etree
import pandas as pd
import io
url = 'https://github.com/cdisc-org/DataExchange-ODM/raw/main/examples/Demographics_RACE/Demographics_RACE_check_all_that_apply.xml'
response = requests.get(url)
tree = response.content
tree = io.BytesIO(tree)
Notice that after storing the HTTP request content in the tree variable using requests, the next step is transforming this content using the io.BytesIO() function. But what exactly are these things?
The io library, which is part of Python's Standard Library, handles raw data in the simplest way possible and temporarily. This means that when we read the content of the request stored in tree, we only read the content without turning it into a much more complex and heavy ODM tree. In other words, the io.BytesIO() function only opens the file and keeps it in a temporary memory space (a buffer) so it can be accessed while the code is running, through a sequence of bytes, as illustrated in the diagram below.
From this point, we can explore the data contained in the tree variable using another method available in lxml.etree, the etree.iterparse.
for _, element in etree.iterparse(io.BytesIO(den_xml2)): #DICA: Como o io.BytesIO(den_xml2) se trata de uma sequência temporária de caracteres, é mais interessante colocá-lo dentro da iteração em vez de tentar armazená-lo numa variável.
...
From here, it's possible to extract the data in a similar way to the method we used in the previous post.
But what's the difference?
You might be wondering what the actual difference is once the suggested changes are applied. It's possible to conduct various performance tests considering execution time and memory usage; but to summarize, look at the graph below, which shows relatively how much memory is used by each function, etree.XML() and io.BytesIO():

Notice that the graph divides between the raw data and the parsed ODM tree (remember the previous diagrams?); since io.BytesIO() only stores the raw data without needing to parse it to access the content, it only uses the space necessary for the bytes of that data to be available. On the other hand, the etree function, besides storing the raw data, has to keep the entire ODM tree available, thus needing more memory. This characteristic is crucial when dealing with XML files that exceed 1GB in size, for example; if we don't have enough memory to hold all the data from the file, we will certainly have numerous problems extracting what we want. Not to mention performance: the greater the memory requirement, the longer it takes to process everything as a result.
In the end, regardless of the size of the XML "monster" you have to deal with, it's still possible to do everything you need in an easier and less painful way using Python. It's up to us now to decide which method best suits each case and continue studying the tools and concepts discussed so far. So, the next time a huge obstacle appears in your path, you can take a moment to breathe, assess, and choose the best tool, so that obstacle becomes a simpler and—why not?—more enjoyable part of the journey.




