

XML na Prática (2): Fazendo (muito) mais com menos
Nada de pânico: se tratando de XML, usando Python, o obstáculo no caminho pode se tornar o próprio caminho.

No último post, vimos como lidar com arquivos ODM-XML usando algumas bibliotecas Python para tanto, fazendo o processo menos temeroso e mais simples.
## Lembra dessas bibliotecas? ##
import requests
from lxml import etree #Neste caso, usamos a API da biblioteca 'ElementTree' que está disponível na biblioteca 'lxml'
import pandas as pd
Essas bibliotecas (especialmente o pandas e o lxml.etree) foram pensados para otimizar a construção e manipulação de conjuntos de dados contidos em um documento XML. No entanto, é possível que encontremos alguns empecilhos no caminho, que não foram abordados no artigo anterior. Aqui estão alguns:
O documento XML é enorme: Anteriormente, utilizamos um arquivo cujo tamanho é pequeno; sabemos que, na vida real, as coisas podem muito bem não vir assim. É possível que caia em nossas mãos um arquivo com 1GB de tamanho para mais;
Você não precisa de todos os dados contidos no arquivo: Para poder manipular um documento XML, bibliotecas como
lxmleElementTreeprecisam, pela própria natureza desse tipo de arquivo, ler e interpretar um XML do início ao fim. Por razões como o problema já mencionado acima, isso custa tempo e memória, afetando a performance do seu script em Python.Você não tem à disposição uma máquina robusta: Os dois problemas acima são muito mais difíceis de resolver quando temos uma máquina mais limitada. Usar plataformas como o Google Colab podem ser uma alternativa de contorno a isso, mas nem sempre podemos lançar mão desse recurso.
A partir disso, você pode pensar algo como “voltei à estaca zero; como é que eu vou conseguir manipular esse bendito XML, e conseguir os dados de que preciso? Será que terei de ir atrás de outra alternativa senão o Python?”
O objetivo desse artigo é mostrar que ainda não é hora de desistir do Python. Mudando algumas coisas no código, você ganhará, com certeza, mais uma chance de enfrentar os “monstros” do XML, e finalmente conseguir extrair os dados e informações tão esperados.
Conhecendo o obstáculo
Para começar, debruçemo-nos em algumas das primeiras linhas de código que estamos utilizando:
from lxml import etree
import requests
url = 'https://github.com/cdisc-org/DataExchange-ODM/raw/main/examples/Demographics_RACE/Demographics_RACE_check_all_that_apply.xml' #Fonte do arquivo .xml que estamos utilizando
response = requests.get(url) #Requisição HTTP
tree = response.content #O conteúdo da requisição
Esse bloco de código, como é visto acima, faz três coisas: 1) Armazena uma string de um endereço URL do GitHub; 2) Faz uma requisição a esse URL via (requests)[https://requests.readthedocs.io/] para obter o conteúdo do mesmo; e 3) Armazena o conteúdo da requisição em uma variável (i.e., o arquivo XML do qual extrairemos os dados).
O próximo passo é transformar o conteúdo da variável tree em algo que pode ser lido e explorado pelo lxml, usando a função XML. Assim:
tree = etree.XML(tree, etree.XMLParser(remove_comments=True))
print(tree)
<Element {http://www.cdisc.org/ns/odm/v2.0}ODM at 0x145a22f7a80>
O processo de parsing, que é o processo aqui realizado pelo lxml.etree, consiste em transformar o conteúdo que foi extraído da URL do GitHub em uma árvore ODM com todos os seus elementos. Com isso, podemos explorar o conteúdo de todo o documento XML de forma completa, uma vez que a árvore de elementos estará na memória do computador, pronta para ser utilizada...
... e é aí que pode estar o problema.
Entendendo o tamanho do problema
Como dito anteriormente, o exemplo que estamos utilizando pode ser considerado pequeno, nos mais variados sentidos. Além do tamanho, podemos assumir que a árvore ODM que é resultado do parsing também não é muito grande. Transferindo o exemplo para o seu computador e executando o script inteiro, é possível que o processamento seja rápido e não ocupe tanta memória.
Para casos mais próximos da vida real, nem sempre é assim. Exemplificando através de uma experiência pessoal, já me encontrei na situação de ter de lidar com arquivos XML que, uma vez transformados em DataFrames do pandas, possuíam mais de 8 milhões de linhas. Para se ter uma ideia, uma planilha do Excel possui um limite de linhas de um pouco mais de 1 milhão. Um verdadeiro "monstro".
Acontece que, para que a árvore ODM possa ser utilizada através de um parse do lxml, ela precisa ser totalmente "destrinchada", precisando alocar na memória, além do nó raiz (que pode ser visto, neste caso, usando o atributo tree.tag no lxml), os nós filhos, ou children, de toda a estrutura. Essa alocação toda não só gera toda uma complexidade da coisa, mas também pode custar muita memória do computador (um exemplo de como isso tudo estaria distribuído na memória é ilustrado no diagrama abaixo).
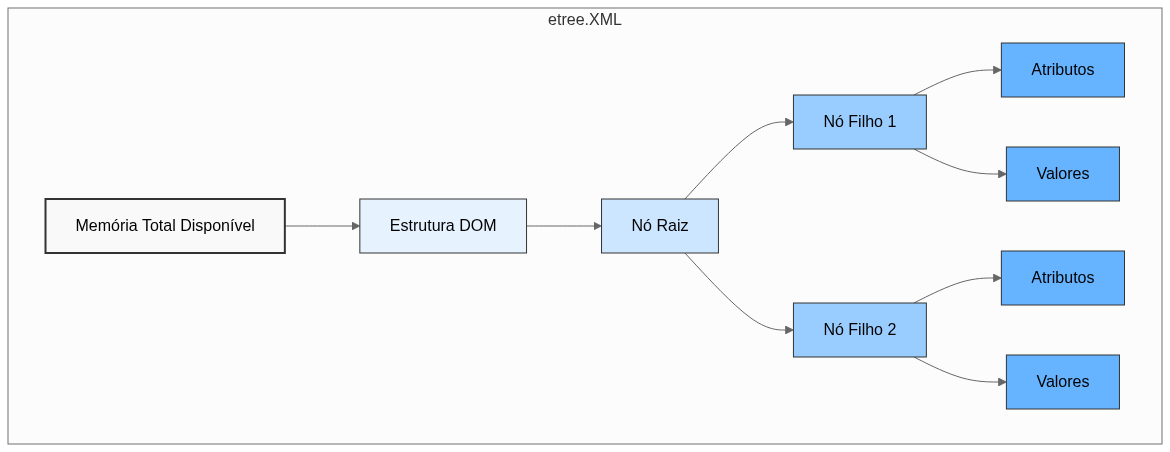
Transformando o obstáculo no caminho
A ideia aqui é, em vez de abrir toda a árvore estrutural do XML e armazenar na memória, abrir os dados sem precisar processar o arquivo, de uma forma temporária, onde nós poderemos ler os dados em sequência. Essa abordagem é especialmente recomendada quando não precisamos de todos os dados contidos no arquivo XML. Para tanto, adicionaremos mais uma biblioteca Python em nossa "caixa de ferramentas": io.
Observe o snippet abaixo:
import requests
from lxml import etree
import pandas as pd
import io
url = 'https://github.com/cdisc-org/DataExchange-ODM/raw/main/examples/Demographics_RACE/Demographics_RACE_check_all_that_apply.xml'
response = requests.get(url)
tree = response.content
tree = io.BytesIO(tree)
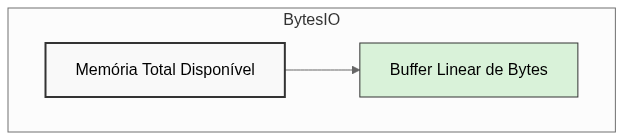
Perceba que, após armazenar o conteúdo da requisição HTTP na variável tree usando o requests, o passo seguinte é a transformação desse conteúdo usando a função io.BytesIO(). Mas, afinal, o que são essas coisas?
A biblioteca io, que compõe a Biblioteca Padrão do Python, vem lidar com os dados brutos da maneira mais simples possível, e de forma temporária. Isso quer dizer que, ao lermos o conteúdo da requisição que foi armazenada em tree, faremos apenas uma leitura do conteúdo, sem torná-lo uma árvore ODM bem mais complexa e pesada. Ou seja, a função io.BytesIO() somente abre o arquivo, e o deixa em um espaço temporário da memória (um buffer) para que seja possível acessá-lo enquanto o código é executado, através de uma sequência de bytes, conforme ilustrado no diagrama abaixo.
A partir disso, podemos realizar uma exploração dos dados contidos na variável tree através de um outro método presente no lxml.etree, o etree.iterparse.
for _, element in etree.iterparse(io.BytesIO(den_xml2)): #DICA: Como o io.BytesIO(den_xml2) se trata de uma sequência temporária de caracteres, é mais interessante colocá-lo dentro da iteração em vez de tentar armazená-lo numa variável.
...
A partir daqui, é possível extrair os dados de maneira semelhante ao método que utilizamos no post anterior.
Mas qual é a diferença?
Você pode estar se perguntando sobre qual é a diferença factual vista uma vez aplicada as mudanças sugeridas. É possível fazer vários testes de performance considerando o tempo de execução e a quantidade de memória utilizada; mas, para resumir, observe o gráfico a seguir, que mostra de maneira relativa o quanto de memória é ocupada por cada função, etree.XML() e io.BytesIO():
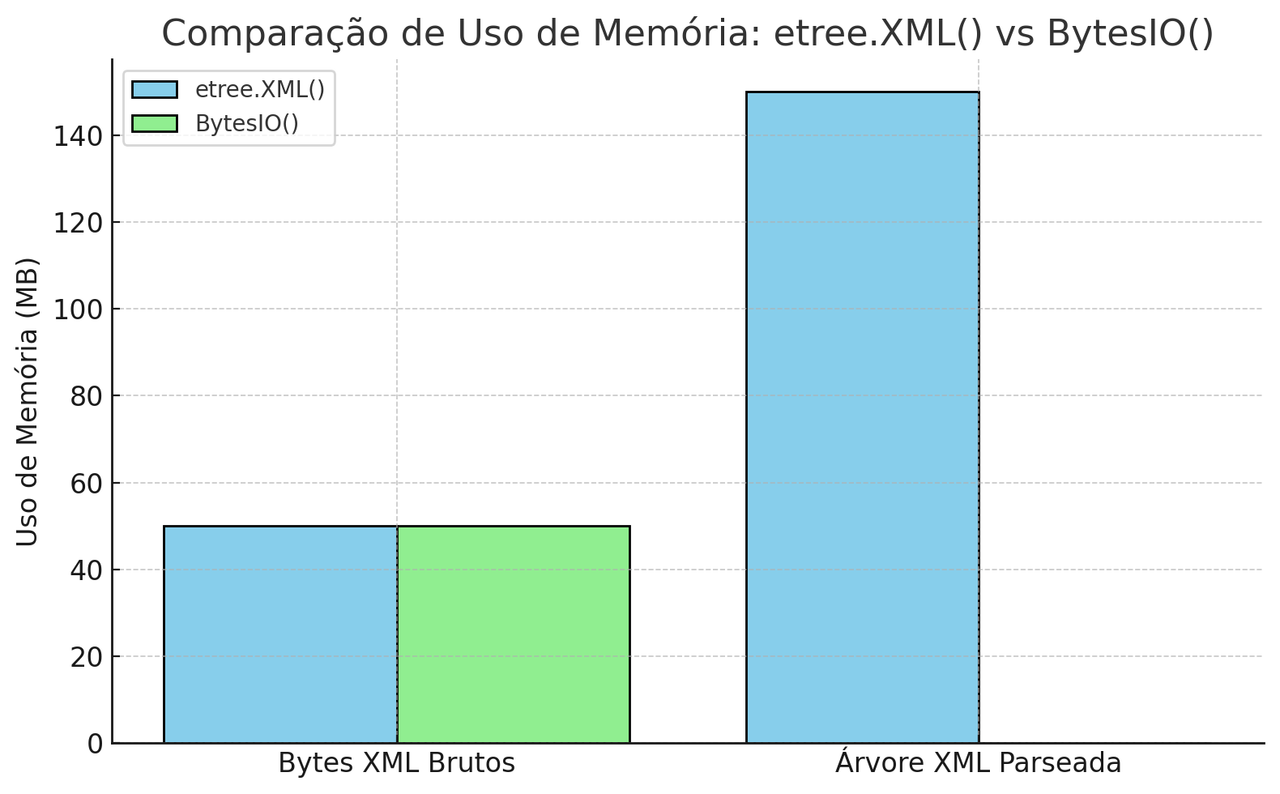
Perceba que o gráfico faz a divisão entre os dados brutos e a árvore ODM parseada (lembra dos diagramas anteriores?); uma vez que o io.BytesIO() apenas armazena os dados brutos, sem precisar fazer nenhum parsing para acessar o conteúdo, ele ocupa apenas o espaço necessário para que os bytes desses dados estejam disponíveis; já a função do etree, além de armazenar os dados brutos, tem de manter disponível a árvore ODM inteira, assim tendo que ocupar mais memória. Essa característica é decisiva na hora de lidarmos com arquivos XML que rompem a barreira dos 1GB de tamanho, por exemplo; se não temos uma quantidade de memória o suficiente para que caiba todos os dados do arquivo, certamente teremos inúmeros problemas para extrair o que queremos. Isso sem falar na performance: quanto maior a necessidade de memória, mais tempo para processarmos tudo, por consequência.
Ao fim e ao cabo, independentemente do tamanho do "monstro" XML com o qual você terá de lidar, ainda é possível fazer tudo que se precisa de uma maneira mais fácil e menos dolorosa usando o Python. Cabe a nós agora decidirmos qual método se adapta melhor a cada caso, e seguir estudando sobre as ferramentas e conceitos que foram abordados até agora. E assim, da próxima vez que um obstáculo enorme aparecer em seu caminho, você pode parar pra respirar, avaliar e escolher a melhor ferramenta, para que esse obstáculo se torne uma parte mais simples e - por que não? - mais divertida do caminho.




