

JSON na Prática: Lidando com o Dataset-JSON em Python
Mais uma vez usando Python, veremos aqui que, quando se trata de dados clínicos, esse JSON é mais bonzinho do que o do cinema.

Contexto
Em estudos clínicos, é comum trabalharmos com conjuntos de dados que podem vir em variados formatos, dependendo do que o sistema EDC escolhido consegue oferecer. Entretanto, em algumas situações, será preciso extrair um conjunto de dados completo, de acordo com o que as entidades regulatórias exigem nas submissões de aprovação do uso de medicamentos e vacinas, principalmente. Dentre os formatos que aparecem como opções mais frequentes, estão o XML (que já vimos anteriormente) , e o JSON. Para aliviar um pouco mais do desespero que às vezes bate quando enfrentamos esses "monstros", hoje é a vez de ver na prática como lidar com um arquivo JSON.
O que é JSON?
JSON é a sigla para JavaScript Object Notation, uma representação de dados que, assim como o XML, pode ser utilizada para transmissões de dados. Como o próprio nome aponta, é baseado em um subconjunto da linguagem JavaScript; no entanto, possui uma estrutura universal, podendo ser lida e manipulada por várias linguagens de programação 1.
Dataset-JSON
O Dataset-JSON é uma iniciativa em desenvolvimento contínuo liderada por CDISC e PHUSE 2, com o objetivo de estabelecer uma alternativa mais leve, rápida, e legível para humanos, dos modelos de transferência de dados clínicos utilizados atualmente (a saber, SAS e Dataset-XML, este último já abordado no blog).
Diferenças entre JSON e XML para armazenamento e transferência de dados
Especialmente nos casos de dados de estudos clínicos, várias fontes apontam que o formato JSON leva certas vantagens sobre o formato XML. Podemos elencar alguns aqui:
O XML, embora já seja um avanço frente a modelos de dados clínicos mais antigos, ainda é um formato de arquivo grande, muito em função da sua natureza verbosa; em uma mesma tag, por exemplo, é possível ter mais de um atributo que represente informações importantes (esse problema, inclusive, foi abordado no segundo post sobre o XML no blog). O JSON possui uma estrutura mais simples e flexível, podendo armazenar a mesma quantidade de informações que um XML num arquivo menor e de leitura mais fácil, economizando memória e energia;
O JSON é inteiramente compatível com APIs, podendo ser visto em versões de EDCs mais novos (como o OpenClinica a partir da versão v. 4.x, e as versões mais novas dos REDCap Acadêmico e Cloud), facilitando a transmissão de dados, sem a necessidade de obrigatoriamente baixar arquivos manualmente 3. O XML, embora esteja presente em algumas APIs, não possui a mesma presença e facilidade do JSON;
O JSON comporta informações básicas sobre as variáveis em seu próprio arquivo; para o XML, embora isso seja possível (como vimos em posts anteriores), não é necessariamente a regra, sendo dependente de arquivos externos 4;
O XML permite a adição de novos namespaces, metadados e outras informações, mas sua estrutura rígida é um fator limitante crítico para tanto. O JSON é muito mais flexível, tendo uma estrutura mais simples e amigável para inserir novos dados.
Vejamos exemplos de como os elementos que formam arquivos XML e JSON são distribuídos na memória quando lidos. O primeiro caso é de uma árvore parecida com o esquema de árvore ODM de arquivos XML que já vimos antes. A árvore XML possui um grau alto de complexidade, evidenciada no diagrama abaixo, sendo que são muitos os elementos que precisam ser armazenados em espaços próprios na memória, fazendo com que seja preciso fazer mais "saltos" entre elementos para conseguir chegar ao dado que se quer.
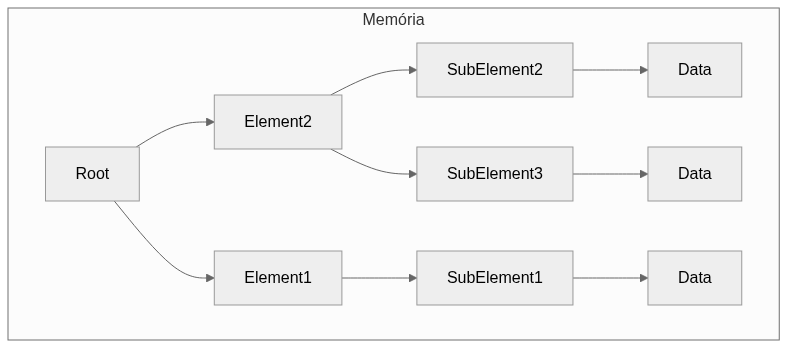
Já quando falamos da árvore de um arquivo JSON, é possível perceber de cara uma redução na complexidade: os dados estão junto dos sub-elementos, fazendo com que o espaço ocupado na memória seja menor, assim como a quantidade de "saltos" feitos aqui, economizando tempo e energia. O esquema está no diagrama abaixo.

Podemos, a partir daqui, fornecer um resumo dessa comparação:
| Aspecto | Dataset-XML | Dataset-JSON |
| Estrutura | Árvore hierárquica com ponteiros para pais/filhos | Objetos aninhados sem ponteiros explícitos |
| Uso de Memória | Alto (4-5x maior que o arquivo original) | Baixo (mais próximo do tamanho original) |
| Complexidade | Alta (necessário manter relações entre nós) | Baixa (estrutura plana com arrays e dicionários) |
| Eficiência | Menos eficiente em termos de acesso | Mais eficiente devido à simplicidade da estrutura |
Usando Python para lidar com JSON
Dados que serão utilizados
Os dados que utilizaremos neste artigo ainda são do repositório do CDISC no GitHub, mas estão em uma pasta à parte dedicada aos arquivos Dataset-JSON. Além do exemplo que será nosso foco aqui, há muitos outros datasets que podem ser visualizados, extraídos, e manipulados à disposição.
Bibliotecas a serem importadas
Ao usarmos o Python para lidar com dados advindos de arquivos JSON, utilizaremos uma biblioteca em específico que é exatamente dedicada a esse tipo de documento: json. Esta é uma biblioteca nativa do Python; portanto, se você está utilizando WinPython ou Anaconda, é muito provável que consiga acessar a ferramenta apenas com uma importação. As outras bibliotecas que serão importadas já são de conhecimento nosso: requests e pandas.
import requests, json
import pandas as pd
Adquirindo e explorando os dados
Para obter os dados que iremos analisar, é possível utilizar passos semelhantes ao que já vimos em posts anteriores, usando a biblioteca requests. Com a função requests.get() enviamos uma requisição ao GitHub para obtermos o arquivo JSON que queremos, e, uma vez bem-sucedida essa requisição, podemos armazenar o conteúdo da mesma em uma variável, example.
Como retratado antes, diferentemente daquilo que fazemos com arquivos XML, usaremos o pacote json para lermos o arquivo resultante da requisição. Para este caso, usamos a função json.loads(), como abaixo.
example = requests.get('https://github.com/cdisc-org/DataExchange-DatasetJson/raw/refs/heads/master/examples/i18n/ae.json')
example = example.content
example = json.loads(example)
O resultado desse "carregamento" é um objeto parecido com o dict do Python, um dicionário 5 6; esse é um dos tipos propostos para JSON quando da leitura do mesmo por algum software ou pacote de linguagem. Neste dicionário, encontraremos todas as informações de que precisamos para identificar os dados e colocá-los em um DataFrame legível e explorável.
Se explorarmos esse dicionário em uma IDE como o Spyder, que está disponível tanto no WinPython, quanto no Anaconda, veremos uma estrutura chave-valor clássica de um dicionário, mas estaremos também vendo outras coisas que nos interessam aqui, conforme a imagem abaixo.

Desde a versão dos metadados, até o número de registros contidos no arquivo JSON, várias informações essenciais do arquivo; foquemo-nos, no entanto, em apenas duas chaves: columns e rows. Nesses valores estarão aquilo que utilizaremos para montarmos o DataFrame em pandas que poderemos explorar mais à frente.
Acessando dados dentro do JSON
Para que seja possível acessar os dados de rows e columns dentro do objeto example, basta que sigamos a lógica de um dicionário em Python, como foi relatado antes. Usando o método object[key], ou objeto[chave], podemos acessar os dados que queremos dentro do dicionário example, usando algo como o bloco abaixo:
columns = example['columns']
rows = example['rows']
Com isso, podemos ter acesso pleno ao conteúdo que iremos utilizar para montar o DataFrame. Se invocarmos o objeto columns no console, será possível ver todo o conteúdo que ele possui.
columns
[{'itemOID': 'IT.AE.STUDYID',
'name': 'STUDYID',
'label': 'Study Identifier',
'dataType': 'string',
'length': 12},
{'itemOID': 'IT.AE.DOMAIN',
'name': 'DOMAIN',
'label': 'Domain Abbreviation',
'dataType': 'string',
'length': 2},
{'itemOID': 'IT.AE.USUBJID',
'name': 'USUBJID',
'label': 'Unique Subject Identifier',
'dataType': 'string',
'length': 11},
{'itemOID': 'IT.AE.AESEQ',
'name': 'AESEQ',
'label': 'Sequence Number',
'dataType': 'float'},
{'itemOID': 'IT.AE.AESPID',
'name': 'AESPID',
'label': 'Sponsor-Defined Identifier',
'dataType': 'string',
'length': 3},
{'itemOID': 'IT.AE.AETERM',
'name': 'AETERM',
'label': 'Reported Term for the Adverse Event',
'dataType': 'string',
'length': 200},
{'itemOID': 'IT.AE.AELLT',
'name': 'AELLT',
'label': 'Lowest Level Term',
'dataType': 'string',
'length': 100},
{'itemOID': 'IT.AE.AELLTCD',
'name': 'AELLTCD',
'label': 'Lowest Level Term Code',
'dataType': 'float'},
{'itemOID': 'IT.AE.AEDECOD',
'name': 'AEDECOD',
'label': 'Dictionary-Derived Term',
'dataType': 'string',
'length': 200},
{'itemOID': 'IT.AE.AEPTCD',
'name': 'AEPTCD',
'label': 'Preferred Term Code',
'dataType': 'float'},
{'itemOID': 'IT.AE.AEHLT',
'name': 'AEHLT',
'label': 'High Level Term',
'dataType': 'string',
'length': 100},
{'itemOID': 'IT.AE.AEHLTCD',
'name': 'AEHLTCD',
'label': 'High Level Term Code',
'dataType': 'float'},
{'itemOID': 'IT.AE.AEHLGT',
'name': 'AEHLGT',
'label': 'High Level Group Term',
'dataType': 'string',
'length': 100},
{'itemOID': 'IT.AE.AEHLGTCD',
'name': 'AEHLGTCD',
'label': 'High Level Group Term Code',
'dataType': 'float'},
{'itemOID': 'IT.AE.AEBODSYS',
'name': 'AEBODSYS',
'label': 'Body System or Organ Class',
'dataType': 'string',
'length': 67},
{'itemOID': 'IT.AE.AEBDSYCD',
'name': 'AEBDSYCD',
'label': 'Body System or Organ Class Code',
'dataType': 'float'},
{'itemOID': 'IT.AE.AESOC',
'name': 'AESOC',
'label': 'Primary System Organ Class',
'dataType': 'string',
'length': 100},
{'itemOID': 'IT.AE.AESOCCD',
'name': 'AESOCCD',
'label': 'Primary System Organ Class Code',
'dataType': 'float'},
{'itemOID': 'IT.AE.AESEV',
'name': 'AESEV',
'label': 'Severity/Intensity',
'dataType': 'string',
'length': 8},
{'itemOID': 'IT.AE.AESER',
'name': 'AESER',
'label': 'Serious Event',
'dataType': 'string',
'length': 1},
{'itemOID': 'IT.AE.AEACN',
'name': 'AEACN',
'label': 'Action Taken with Study Treatment',
'dataType': 'string',
'length': 30},
{'itemOID': 'IT.AE.AEREL',
'name': 'AEREL',
'label': 'Causality',
'dataType': 'string',
'length': 8},
{'itemOID': 'IT.AE.AEOUT',
'name': 'AEOUT',
'label': 'Outcome of Adverse Event',
'dataType': 'string',
'length': 200},
{'itemOID': 'IT.AE.AESCAN',
'name': 'AESCAN',
'label': 'Involves Cancer',
'dataType': 'string',
'length': 1},
{'itemOID': 'IT.AE.AESCONG',
'name': 'AESCONG',
'label': 'Congenital Anomaly or Birth Defect',
'dataType': 'string',
'length': 1},
{'itemOID': 'IT.AE.AESDISAB',
'name': 'AESDISAB',
'label': 'Persist or Signif Disability/Incapacity',
'dataType': 'string',
'length': 1},
{'itemOID': 'IT.AE.AESDTH',
'name': 'AESDTH',
'label': 'Results in Death',
'dataType': 'string',
'length': 1},
{'itemOID': 'IT.AE.AESHOSP',
'name': 'AESHOSP',
'label': 'Requires or Prolongs Hospitalization',
'dataType': 'string',
'length': 1},
{'itemOID': 'IT.AE.AESLIFE',
'name': 'AESLIFE',
'label': 'Is Life Threatening',
'dataType': 'string',
'length': 1},
{'itemOID': 'IT.AE.AESOD',
'name': 'AESOD',
'label': 'Occurred with Overdose',
'dataType': 'string',
'length': 1},
{'itemOID': 'IT.AE.AEDTC',
'name': 'AEDTC',
'label': 'Date/Time of Collection',
'dataType': 'string',
'length': 10},
{'itemOID': 'IT.AE.AESTDTC',
'name': 'AESTDTC',
'label': 'Start Date/Time of Adverse Event',
'dataType': 'string',
'length': 10},
{'itemOID': 'IT.AE.AEENDTC',
'name': 'AEENDTC',
'label': 'End Date/Time of Adverse Event',
'dataType': 'string',
'length': 10},
{'itemOID': 'IT.AE.AESTDY',
'name': 'AESTDY',
'label': 'Study Day of Start of Adverse Event',
'dataType': 'float'},
{'itemOID': 'IT.AE.AEENDY',
'name': 'AEENDY',
'label': 'Study Day of End of Adverse Event',
'dataType': 'float'},
{'itemOID': 'IT.AE.AETRTEM',
'name': 'AETRTEM',
'label': 'TREATMENT EMERGENT FLAG',
'dataType': 'string',
'length': 1}]
Perceba que, quando acessamos o columns, não tempos apenas o nome da coluna, mas também o que ela significa (através do label), tipo de dado (através do dataType), além do OID, que é o identificador do objeto 7. Isso evidencia a facilidade do JSON de comportar e acessar os metadados do arquivo, uma vantagem frente ao XML que, embora exista a possibilidade de acesso dos metadados em um mesmo arquivo, isso não é feito de forma tão facilitada.
Indo adiante, para vermos o que o objeto rows possui, usamos a mesmo método de antes. Como é esperado que o número de registros seja grande (ao verificarmos na chave recordsdo dicionário, temos 1191 registros!), veremos apenas a primeira ocorrência, neste caso.
rows[0] #A primeira ocorrência dentro da lista 'rows'
['CDISCPILOT01',
'AE',
'01-701-1015',
1,
'E07',
'アプリケーションサイトの紅斑',
'APPLICATION SITE REDNESS',
None,
'APPLICATION SITE ERYTHEMA',
12345678,
'HLT_0617',
12345678,
'HLGT_0152',
12345678,
'GENERAL DISORDERS AND ADMINISTRATION SITE CONDITIONS',
87654321,
'GENERAL DISORDERS AND ADMINISTRATION SITE CONDITIONS',
None,
'MILD',
'N',
'',
'PROBABLE',
'NOT RECOVERED/NOT RESOLVED',
'N',
'N',
'N',
'N',
'N',
'N',
'N',
'2014-01-16',
'2014-01-03',
'',
2,
None,
'Y']
Perceba a ordem em que estão os dados; é de se esperar que, uma vez que "liguemos" as linhas às colunas, cada dado nessa lista comece a fazer sentido. Essa mesma ordem aparecerá em todas as outras linhas encontradas nesse objeto, que estão cada uma em uma lista separada.
Montando um DataFrame de um jeito simples
Para montarmos o DataFrame, primeiro é preciso ter duas coisas em mente: 1) Já temos as linhas da nossa tabela na variável rows, de forma (que se espera ser) ordenada; e 2) Temos as definições de nomes das colunas no objeto columns, em forma de dicionários em uma lista. Então, antes de usarmos o pandas para montarmos de vez o DataFrame, primeiro precisamos separar aquilo que serão os nomes das colunas da tabela. Para isso, basta criarmos uma lista data, que será populada com os rótulos, ou labels de uma iteração a partir da chave columns no nosso primeiro dicionário, example. Sendo columns uma lista com vários dicionários, basta com que a gente acesse cada dicionário dentro dessa lista, e extraia o label usando o princípio objeto[chave]. A partir disso, temos os rótulos de cada coluna, uma vez que são os valores de label dentro de cada dicionário.
data = [] #A lista a ser populada
for cl in example['columns']: #Iteração para extrairmos os rótulos
data.append(cl['label'])
data #Acessar os dados da lista já populada
['Study Identifier',
'Domain Abbreviation',
'Unique Subject Identifier',
'Sequence Number',
'Sponsor-Defined Identifier',
'Reported Term for the Adverse Event',
'Lowest Level Term',
'Lowest Level Term Code',
'Dictionary-Derived Term',
'Preferred Term Code',
'High Level Term',
'High Level Term Code',
'High Level Group Term',
'High Level Group Term Code',
'Body System or Organ Class',
'Body System or Organ Class Code',
'Primary System Organ Class',
'Primary System Organ Class Code',
'Severity/Intensity',
'Serious Event',
'Action Taken with Study Treatment',
'Causality',
'Outcome of Adverse Event',
'Involves Cancer',
'Congenital Anomaly or Birth Defect',
'Persist or Signif Disability/Incapacity',
'Results in Death',
'Requires or Prolongs Hospitalization',
'Is Life Threatening',
'Occurred with Overdose',
'Date/Time of Collection',
'Start Date/Time of Adverse Event',
'End Date/Time of Adverse Event',
'Study Day of Start of Adverse Event',
'Study Day of End of Adverse Event',
'TREATMENT EMERGENT FLAG']
Feito isso, o retorno que vemos é uma lista de nomes que utilizaremos para identificar cada coluna do nosso futuro DataFrame.
Com todo esse processo realizado, e com todos esses dados em mãos, já é hora de juntarmos tudo isso em um mesmo DataFrame; para tanto, lançaremos mão da função pd.DataFrame(), onde indicaremos onde está os dados que estarão nas linhas, rows, e os nomes das colunas, utilizando o argumento columns e o objeto data.
df = pd.DataFrame(rows, columns=data)
Uma vez integrado tudo em um DataFrame, basta salvar com o formato de preferência. A partir daqui, os dados semi-estruturados do JSON passam a ser dados estruturados de uma planilha.
## Exportando
df.to_csv('df.csv') #Arquivo .csv
df.to_excel('df.xlsx') #Arquivo .xlsx
df.to_parquet('df.parquet') #Arquivo .parquet
Notas do artigo
1. Mais informações sobre isso podem ser vistas na página oficial do JSON, que está traduzida em português, inclusive: https://www.json.org/json-pt.html ↩
2. O PHUSE é uma associação sem fins lucrativos que reúne pessoas que compartilham ideias e soluções envolvendo dados clínicos, como analisá-los e, posteriormente reportá-los. Muitas das inovações em dados envolvendo ensaios clínicos, certamente, virão dessa associação; portanto, vale muito a pena acompanhá-los via https://phuse.global/. ↩
3. PHUSE. https://phuse.s3.eu-central-1.amazonaws.com/Deliverables/Optimizing+the+Use+of+Data+Standards/WP-88+Dataset-JSON+Report.pdf ↩
4. "Another concern raised about Dataset-XML has been that the metadata - Define-XML - is completely separated from the data. To be able to process a Dataset-XML file one always needs the associated Define-XML document." Lex Jansen (https://www.lexjansen.com/pharmasug/2022/AD/PharmaSUG-2022-AD-150_ppt.pdf) ↩
5. "Python JSON is similar to a Python dictionary in that it stores data in key-value pairs enclosed in curly brackets ({}). However, double quotation marks around the JSON key are required in this case." Como visto em https://www.boardinfinity.com/blog/dict-to-json-in-python/ ↩
6. As diferenças entre objetos JSON e dict podem ser vistas neste artigo do GeeksforGeeks, de forma detalhada: https://www.geeksforgeeks.org/difference-between-json-and-dictionary-in-python/ ↩
7. O identificador do objeto varia de documento para documento, EDC para EDC. Usando um EDC específico, o OpenClinica, vemos como esse assunto é tratado na documentação, aqui: https://docs.openclinica.com/3-1-technical-documents/openclinica-and-cdisc-odm-specifications/openclinica-and-cdisc-odm-specifications-cdisc-odm-representation-openclin-6/ ↩



