

Unlocking the Power of JSON in Clinical Data Management: A Practical Guide
Explore the advantages of JSON for clinical data processes with Python.

Context
In clinical studies, we often work with datasets that can come in various formats, depending on what the chosen EDC system can offer. However, in some situations, it will be necessary to extract a complete dataset according to what regulatory entities require for the approval submissions of drug and vaccine use, mainly. Among the formats that frequently appear as options are XML (which we have seen previously), and JSON. To ease the anxiety that sometimes arises when facing these "monsters," today we'll see in practice how to handle a JSON file.
What is JSON?
JSON stands for JavaScript Object Notation, a data representation that, like XML, can be used for data transmission. As the name suggests, it is based on a subset of the JavaScript language; however, it has a universal structure that can be read and manipulated by various programming languages 1.
Dataset-JSON
Dataset-JSON is an ongoing initiative led by CDISC and PHUSE 2, aiming to establish a lighter, faster, and more human-readable alternative to the current clinical data transfer models (namely, SAS and Dataset-XML, the latter already discussed on the blog).
Differences between JSON and XML for Data Storage and Transfer
Especially in the case of clinical study data, various sources indicate that the JSON format has certain advantages over the XML format. We can list a few here:
XML, although an improvement over older clinical data models, is still a large file format, mainly due to its verbose nature. In a single tag, for example, there can be more than one attribute representing important information (this issue was discussed in the second post about XML on the blog). JSON has a simpler and more flexible structure, capable of storing the same amount of information as XML in a smaller, easier-to-read file, saving memory and energy.
JSON is fully compatible with APIs and can be seen in newer versions of EDCs (such as OpenClinica from version v. 4.x, and the latest versions of REDCap Academic and Cloud), making data transmission easier without the need to manually download files 3. XML, although present in some APIs, does not have the same presence and ease as JSON.
JSON contains basic information about the variables within its own file. For XML, although this is possible (as we have seen in previous posts), it is not necessarily the rule and often depends on external files 4.
XML allows the addition of new namespaces, metadata, and other information, but its rigid structure is a critical limiting factor for this. JSON is much more flexible, with a simpler and more user-friendly structure for adding new data.
Let's look at examples of how the elements that make up XML and JSON files are distributed in memory when read. The first case is a tree similar to the ODM tree schema of XML files we have seen before. The XML tree has a high degree of complexity, as shown in the diagram below, with many elements needing to be stored in their own memory spaces. This requires more "jumps" between elements to reach the desired data.
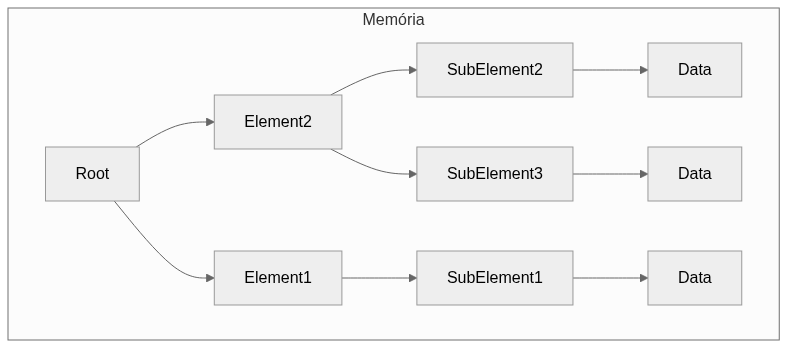
When we talk about the tree of a JSON file, you can immediately notice a reduction in complexity: the data is with the sub-elements, which means it takes up less space in memory and requires fewer "jumps" here, saving time and energy. The diagram is below.

From here, we can provide a summary of this comparison:
| Aspect | Dataset-XML | Dataset-JSON |
| Structure | Hierarchical tree with pointers to parents/children | Objects nested without explicit pointers |
| Memory usage | High (4-5x larger than the original file) | Low (closer to the original size) |
| Complexity | High (necessary to maintain relationships between nodes) | Low (flat structure with arrays and dictionaries) |
| Efficiency | Less efficient in terms of access | More efficient due to the simplicity of the structure |
Using Python to handle JSON
Data to be Used
The data we will use in this article is still from the CDISC repository on GitHub, but it is in a separate folder dedicated to Dataset-JSON files. Besides the example that will be our focus here, there are many other datasets available that can be viewed, extracted, and manipulated.
Libraries to be Imported
When using Python to handle data from JSON files, we will use a specific library dedicated to this type of document: json. This is a native Python library, so if you are using WinPython or Anaconda, you can likely access the tool with just an import. The other libraries to be imported are ones we are already familiar with: requests and pandas.
import requests, json
import pandas as pd
Acquiring and Exploring the Data
To get the data we will analyze, you can follow similar steps to those we've seen in previous posts using the requests library. With the requests.get() function, we send a request to GitHub to obtain the JSON file we want, and once this request is successful, we can store its content in a variable, example.
As mentioned before, unlike what we do with XML files, we will use the json package to read the file resulting from the request. For this case, we use the json.loads() function, as shown below.
example = requests.get('https://github.com/cdisc-org/DataExchange-DatasetJson/raw/refs/heads/master/examples/i18n/ae.json')
example = example.content
example = json.loads(example)
The result of this "loading" is an object similar to Python's dict, a dictionary 5 6; this is one of the types proposed for JSON when it is read by some software or language package. In this dictionary, we will find all the information we need to identify the data and put it into a readable and explorable DataFrame.
If we explore this dictionary in an IDE like Spyder, which is available in both WinPython and Anaconda, we will see a classic key-value structure of a dictionary, but we will also see other things that interest us here, as shown in the image below.

From the metadata version to the number of records contained in the JSON file, there are several essential pieces of information in the file. However, let's focus on just two keys: columns and rows. These values will be used to build the pandas DataFrame that we can explore later.
Accessing Data Within the JSON
To access the data in rows and columns within the example object, we just need to follow the logic of a Python dictionary, as mentioned earlier. By using the method object[key], or objeto[chave], we can access the data we want within the example dictionary, using something like the block below:
columns = example['columns']
rows = example['rows']
With this, we can have full access to the content we will use to build the DataFrame. If we call the columns object in the console, we will be able to see all the content it contains.
columns
[{'itemOID': 'IT.AE.STUDYID',
'name': 'STUDYID',
'label': 'Study Identifier',
'dataType': 'string',
'length': 12},
{'itemOID': 'IT.AE.DOMAIN',
'name': 'DOMAIN',
'label': 'Domain Abbreviation',
'dataType': 'string',
'length': 2},
{'itemOID': 'IT.AE.USUBJID',
'name': 'USUBJID',
'label': 'Unique Subject Identifier',
'dataType': 'string',
'length': 11},
{'itemOID': 'IT.AE.AESEQ',
'name': 'AESEQ',
'label': 'Sequence Number',
'dataType': 'float'},
{'itemOID': 'IT.AE.AESPID',
'name': 'AESPID',
'label': 'Sponsor-Defined Identifier',
'dataType': 'string',
'length': 3},
{'itemOID': 'IT.AE.AETERM',
'name': 'AETERM',
'label': 'Reported Term for the Adverse Event',
'dataType': 'string',
'length': 200},
{'itemOID': 'IT.AE.AELLT',
'name': 'AELLT',
'label': 'Lowest Level Term',
'dataType': 'string',
'length': 100},
{'itemOID': 'IT.AE.AELLTCD',
'name': 'AELLTCD',
'label': 'Lowest Level Term Code',
'dataType': 'float'},
{'itemOID': 'IT.AE.AEDECOD',
'name': 'AEDECOD',
'label': 'Dictionary-Derived Term',
'dataType': 'string',
'length': 200},
{'itemOID': 'IT.AE.AEPTCD',
'name': 'AEPTCD',
'label': 'Preferred Term Code',
'dataType': 'float'},
{'itemOID': 'IT.AE.AEHLT',
'name': 'AEHLT',
'label': 'High Level Term',
'dataType': 'string',
'length': 100},
{'itemOID': 'IT.AE.AEHLTCD',
'name': 'AEHLTCD',
'label': 'High Level Term Code',
'dataType': 'float'},
{'itemOID': 'IT.AE.AEHLGT',
'name': 'AEHLGT',
'label': 'High Level Group Term',
'dataType': 'string',
'length': 100},
{'itemOID': 'IT.AE.AEHLGTCD',
'name': 'AEHLGTCD',
'label': 'High Level Group Term Code',
'dataType': 'float'},
{'itemOID': 'IT.AE.AEBODSYS',
'name': 'AEBODSYS',
'label': 'Body System or Organ Class',
'dataType': 'string',
'length': 67},
{'itemOID': 'IT.AE.AEBDSYCD',
'name': 'AEBDSYCD',
'label': 'Body System or Organ Class Code',
'dataType': 'float'},
{'itemOID': 'IT.AE.AESOC',
'name': 'AESOC',
'label': 'Primary System Organ Class',
'dataType': 'string',
'length': 100},
{'itemOID': 'IT.AE.AESOCCD',
'name': 'AESOCCD',
'label': 'Primary System Organ Class Code',
'dataType': 'float'},
{'itemOID': 'IT.AE.AESEV',
'name': 'AESEV',
'label': 'Severity/Intensity',
'dataType': 'string',
'length': 8},
{'itemOID': 'IT.AE.AESER',
'name': 'AESER',
'label': 'Serious Event',
'dataType': 'string',
'length': 1},
{'itemOID': 'IT.AE.AEACN',
'name': 'AEACN',
'label': 'Action Taken with Study Treatment',
'dataType': 'string',
'length': 30},
{'itemOID': 'IT.AE.AEREL',
'name': 'AEREL',
'label': 'Causality',
'dataType': 'string',
'length': 8},
{'itemOID': 'IT.AE.AEOUT',
'name': 'AEOUT',
'label': 'Outcome of Adverse Event',
'dataType': 'string',
'length': 200},
{'itemOID': 'IT.AE.AESCAN',
'name': 'AESCAN',
'label': 'Involves Cancer',
'dataType': 'string',
'length': 1},
{'itemOID': 'IT.AE.AESCONG',
'name': 'AESCONG',
'label': 'Congenital Anomaly or Birth Defect',
'dataType': 'string',
'length': 1},
{'itemOID': 'IT.AE.AESDISAB',
'name': 'AESDISAB',
'label': 'Persist or Signif Disability/Incapacity',
'dataType': 'string',
'length': 1},
{'itemOID': 'IT.AE.AESDTH',
'name': 'AESDTH',
'label': 'Results in Death',
'dataType': 'string',
'length': 1},
{'itemOID': 'IT.AE.AESHOSP',
'name': 'AESHOSP',
'label': 'Requires or Prolongs Hospitalization',
'dataType': 'string',
'length': 1},
{'itemOID': 'IT.AE.AESLIFE',
'name': 'AESLIFE',
'label': 'Is Life Threatening',
'dataType': 'string',
'length': 1},
{'itemOID': 'IT.AE.AESOD',
'name': 'AESOD',
'label': 'Occurred with Overdose',
'dataType': 'string',
'length': 1},
{'itemOID': 'IT.AE.AEDTC',
'name': 'AEDTC',
'label': 'Date/Time of Collection',
'dataType': 'string',
'length': 10},
{'itemOID': 'IT.AE.AESTDTC',
'name': 'AESTDTC',
'label': 'Start Date/Time of Adverse Event',
'dataType': 'string',
'length': 10},
{'itemOID': 'IT.AE.AEENDTC',
'name': 'AEENDTC',
'label': 'End Date/Time of Adverse Event',
'dataType': 'string',
'length': 10},
{'itemOID': 'IT.AE.AESTDY',
'name': 'AESTDY',
'label': 'Study Day of Start of Adverse Event',
'dataType': 'float'},
{'itemOID': 'IT.AE.AEENDY',
'name': 'AEENDY',
'label': 'Study Day of End of Adverse Event',
'dataType': 'float'},
{'itemOID': 'IT.AE.AETRTEM',
'name': 'AETRTEM',
'label': 'TREATMENT EMERGENT FLAG',
'dataType': 'string',
'length': 1}]
Notice that when we access columns, we not only have the column name but also what it means (through the label), the data type (through the dataType), and the OID, which is the object identifier 7. This highlights the ease with which JSON can handle and access file metadata, an advantage over XML, which, although it allows metadata access in the same file, does not do so as easily.
Moving forward, to see what the rows object contains, we use the same method as before. Since it is expected that the number of records is large (when we check the records key in the dictionary, we have 1191 records!), we will only look at the first occurrence in this case.
rows[0] #The first occurrence inside 'rows'
['CDISCPILOT01',
'AE',
'01-701-1015',
1,
'E07',
'アプリケーションサイトの紅斑',
'APPLICATION SITE REDNESS',
None,
'APPLICATION SITE ERYTHEMA',
12345678,
'HLT_0617',
12345678,
'HLGT_0152',
12345678,
'GENERAL DISORDERS AND ADMINISTRATION SITE CONDITIONS',
87654321,
'GENERAL DISORDERS AND ADMINISTRATION SITE CONDITIONS',
None,
'MILD',
'N',
'',
'PROBABLE',
'NOT RECOVERED/NOT RESOLVED',
'N',
'N',
'N',
'N',
'N',
'N',
'N',
'2014-01-16',
'2014-01-03',
'',
2,
None,
'Y']
Notice the order of the data; it is expected that once we "link" the rows to the columns, each piece of data in this list will start to make sense. This same order will appear in all other rows found in this object, each in a separate list.
Building a DataFrame Simply
To build the DataFrame, you need to keep two things in mind: 1) We already have the rows of our table in the rows variable, which is expected to be ordered; and 2) We have the column name definitions in the columns object, as dictionaries in a list. So, before we use pandas to finally build the DataFrame, we first need to separate what will be the column names of the table. To do this, we just need to create a data list, which will be populated with the labels from an iteration using the columns key in our first dictionary, example. Since columns is a list with several dictionaries, we just need to access each dictionary within this list and extract the label using the object[key] principle. From this, we have the labels for each column, as they are the label values within each dictionary.
data = [] #List to be populated
for cl in example['columns']: #An iteraction in order to extract the labels
data.append(cl['label'])
data #See which labels appear
['Study Identifier',
'Domain Abbreviation',
'Unique Subject Identifier',
'Sequence Number',
'Sponsor-Defined Identifier',
'Reported Term for the Adverse Event',
'Lowest Level Term',
'Lowest Level Term Code',
'Dictionary-Derived Term',
'Preferred Term Code',
'High Level Term',
'High Level Term Code',
'High Level Group Term',
'High Level Group Term Code',
'Body System or Organ Class',
'Body System or Organ Class Code',
'Primary System Organ Class',
'Primary System Organ Class Code',
'Severity/Intensity',
'Serious Event',
'Action Taken with Study Treatment',
'Causality',
'Outcome of Adverse Event',
'Involves Cancer',
'Congenital Anomaly or Birth Defect',
'Persist or Signif Disability/Incapacity',
'Results in Death',
'Requires or Prolongs Hospitalization',
'Is Life Threatening',
'Occurred with Overdose',
'Date/Time of Collection',
'Start Date/Time of Adverse Event',
'End Date/Time of Adverse Event',
'Study Day of Start of Adverse Event',
'Study Day of End of Adverse Event',
'TREATMENT EMERGENT FLAG']
Once this is done, the return we see is a list of names that we will use to identify each column of our future DataFrame.
With this process completed and all this data in hand, it's time to put everything together in a single DataFrame. To do this, we'll use the pd.DataFrame() function, where we will specify where the data for the rows is located, using rows, and the column names, using the columns argument and the data object.
df = pd.DataFrame(rows, columns=data)
Once everything is integrated into a DataFrame, simply save it in your preferred format. From here, the semi-structured JSON data becomes structured spreadsheet data.
## Exporting
df.to_csv('df.csv') #.csv file
df.to_excel('df.xlsx') #.xlsx file
df.to_parquet('df.parquet') #.parquet file
Notes
1. More information about this can be found on the official JSON page: https://www.json.org/ ↩
2. PHUSE is a nonprofit organization that brings together people who share ideas and solutions involving clinical data, such as analyzing and subsequently reporting it. Many innovations in data involving clinical trials will certainly come from this organization; therefore, it's definitely worth following them at https://phuse.global/. ↩
3. PHUSE. https://phuse.s3.eu-central-1.amazonaws.com/Deliverables/Optimizing+the+Use+of+Data+Standards/WP-88+Dataset-JSON+Report.pdf ↩
4. "Another concern raised about Dataset-XML has been that the metadata - Define-XML - is completely separated from the data. To be able to process a Dataset-XML file one always needs the associated Define-XML document." Lex Jansen (https://www.lexjansen.com/pharmasug/2022/AD/PharmaSUG-2022-AD-150_ppt.pdf) ↩
5. "Python JSON is similar to a Python dictionary in that it stores data in key-value pairs enclosed in curly brackets ({}). However, double quotation marks around the JSON key are required in this case." Como visto em https://www.boardinfinity.com/blog/dict-to-json-in-python/ ↩
6. The differences between JSON objects and dict can be seen in detail in this GeeksforGeeks article: https://www.geeksforgeeks.org/difference-between-json-and-dictionary-in-python/ ↩
7. The object identifier varies from document to document, EDC to EDC. Using a specific EDC, OpenClinica, we see how this issue is addressed in the documentation here: https://docs.openclinica.com/3-1-technical-documents/openclinica-and-cdisc-odm-specifications/openclinica-and-cdisc-odm-specifications-cdisc-odm-representation-openclin-6/ ↩



