

Aula 10.2 - Análise e visualização de dados em Python - biblioteca pandas (parte 7)
Se duas cabeças juntas pensam melhor que uma, o que dizer de dois conjuntos de dados?

Na última aula, nós vimos as possibilidades de juntar conjuntos de dados em um só usando a função concat() do pandas. Agora, e se quisermos juntar os nossos dados de uma maneira que a concatenação não consegue cobrir?
O pandas, como vimos até então, é uma espécie de 'canivete suíço' para quem quer analisar seus dados; muito por isso, a biblioteca nos oferece mais funções para que possamos 'aliviar a dor' de juntar conjuntos de dados que temos em mãos. Nesta aula, a função da vez é a merge().
Junte-se a nós... mas de que jeito?: função merge()
Ainda mencionando a função concat(), vimos que ela funciona de maneira que se consiga empilhar dois ou mais DataFrames, seja um em cima do outro, seja um do lado do outro. Isso funciona bem para dados que possuam colunas exatamente iguais, ou até mesmo índices... mas e se não for o seu caso?
Se você conhece um pouco de SQL, é capaz de se lembrar de uma cláusula chamada JOIN. Como o próprio nome diz, é uma cláusula destinada a juntar dois conjutos de dados, num primeiro momento, em apenas um, podendo considerar diferentes aspectos para gerar o resultado esperado.
A função merge() do pandas, em bom português, possui poder semelhante ao JOIN; logo, você pode lançar mão dessa função para juntar DataFrames. Mas cuidado: assim como foi dito muitas vezes no universo de Homem-Aranha, "com grandes poderes vêm grandes responsabilidades". A pergunta que fica depois disso é: quais são as "responsabilidades" do merge()?
Como juntar? O parâmetro how
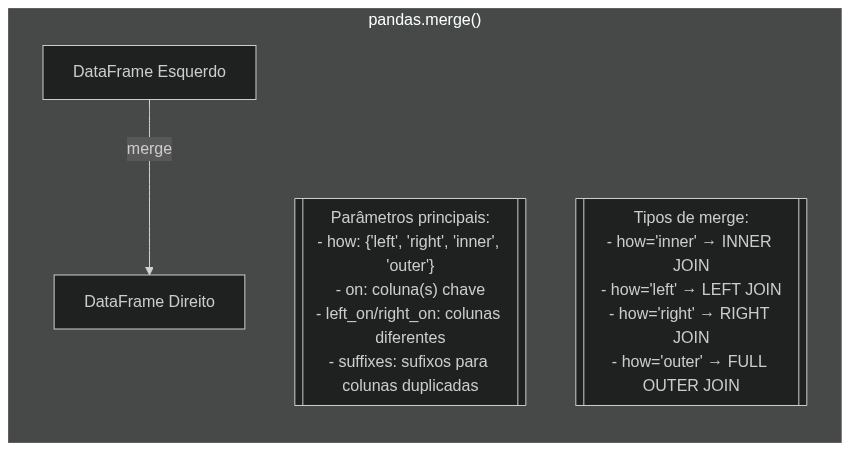
Caso voltemos nossos olhos à documentação do pandas, especialmente no que toca à função merge(), percebemos a presença de um grande número de parâmetros, onde você pode fazer várias modificações a fim de performar uma "sintonia fina", para chegar ao resultado que se espera. No entanto, demos foco primeiramente a um dos mais importantes: o parâmetro how.
Pensemos primeiro na cláusula JOIN do SQL: esta se desdobra em métodos específicos de mescla, como OUTER JOIN, INNER JOIN, e assim por diante. A mesma coisa pode ser vista na função merge(), através do argumento how; a diferença estará na sintaxe, basicamente.
Observe a tabela e a imagem abaixo, onde estão as diferenças de sintaxe entre o pandas e o SQL, e quais são as possibilidades de usar cada função e cláusula. Perceba que os nomes já indicam que tipo de operação será feita; mas, ainda assim, veremos com um pouco mais de detalhe cada uma delas mais à frente.
| pandas merge() | SQL JOIN | Operação |
|---|---|---|
| how='inner' | INNER JOIN | Retorna apenas registros que correspondem em ambas as fontes |
| how='left' | LEFT JOIN | Retorna todos os registros da fonte esquerda + correspondências da direita |
| how='right' | RIGHT JOIN | Retorna todos os registros da fonte direita + correspondências da esquerda |
| how='outer' | FULL OUTER JOIN | Retorna todos os registros de ambas as fontes |
Quem está dentro, quem está fora: inner e outer
Examinemos com um pouco mais de detalhe as operações inner e outer. Para estabelecer comparações com as outras operações, estas duas primeiras consideram as duas fontes, ou tabelas, na sua totalidade. Isso quer dizer que, no momento da atuação do pandas, este dará o mesmo foco para quaisquer dados que apareçam para o mesmo juntar. Aqui, a diferença estará no que sairá de resultado.
A operação outer é, digamos, a mais simples dentre as que estamos analisando. Isso porque a única coisa que o pandas faz é juntar aquilo que aparece nas duas fontes igualmente, e incluir aquilo que aparece ou em uma, ou em outra fonte.
df = pd.merge(df1, df2, how='outer')
A operação inner, por sua vez, é marcada pelo fato de haver a separação de apenas aquilo que aparece nas duas tabelas/fontes que estamos analisando; ou seja, o que é comum entre os dois conjuntos de dados. O que é único dentro de cada conjunto fica fora do resultado.
df = pd.merge(df1, df2, how='inner')
Considerando um ou outro: left e right
Podemos dizer que as operações left e right, diferente das duas anteriores, estabelecem um foco especial em apenas uma das duas fontes, por vez. E isso se dá a partir da posição das tabelas no código que escrevemos. "Como assim?", você deve estar se perguntando. Explico:
- Assim como nas línguas portuguesa, inglesa, e tantas outras, o sentido de leitura de um código Python se dá da esquerda para a direita. Imagine uma operação matemática simples:
5 + 2 + 3 + 125, somamos com o2, e assim por diante, até chegarmos ao resultado.22 - Com as fontes que usaremos para a mescla, é basicamente a mesma coisa. Observe a seguinte linha de código:
pd.merge(df1, df2, how='left', on='ID')df1assumirá a posição da esquerda, enquantodf2assume a posição da direita.
A partir disso, a diferença entre left e right como operações do parâmetro how fica bem mais clara. Ao utilizarmos o primeiro, damos foco à fonte de dados da esquerda, adquirindo da outra fonte à direita apenas o que é semelhante a ambos. Já o right tem como foco a tabela da direita, operando da mesma forma.
Cadê a chave? O parâmetro on
Até aqui, foi possível entender de que forma a função merge() funciona no que se refere a de que jeito vamos mesclar os conjuntos de dados que temos, de acordo com o foco que o pandas dará em relação às tabelas e suas posições. Tendo esse conhecimento adquirido, já é possível lançar mão da função para fazer mesclas.
Entretanto, em muitos casos, a indicação das posições por si só não fará com que alcancemos o resultado que estamos esperando, uma vez que, caso tenhamos uma ou mais colunas em comum para os dois conjuntos de dados, uma mescla 'pura' pode gerar duplicidades, alteração em colunas que possuem nomes iguais... em suma, isso vem gerar uma confusão que nos dará mais trabalho depois. Mas, na própria função merge(), há uma solução simples: apontar as chaves de cada tabela, a partir do parâmetro on.
Voltando ao SQL e adicionando um pouco de conceitos básicos de banco de dados, sabemos que, em um conjunto de dados dentro de um banco é possível ter o que chamamos de chaves; estas nada mais são do que valores únicos pelos quais podemos identificar dados dentro de uma tabela.
Para entender melhor, imaginemos o seguinte: Temos em mãos dois DataFrames com dados envolvendo características corpóreas de certas espécies de mamíferos, conforme o bloco de código a seguir:
import pandas as pd
import numpy as np
# Criando o primeiro DataFrame com características físicas principais
df1 = pd.DataFrame({
'Especie': ['Leão', 'Tigre', 'Urso Pardo', 'Lobo Cinzento', 'Jaguar'],
'comprimento_cm': [250, 300, 200, 150, 180],
'tamanho_pes_cm': [18, 20, 25, 15, 16],
'tamanho_presas_cm': [8, 7.5, 5, 6, 7]
})
# Criando o segundo DataFrame com características faciais
df2 = pd.DataFrame({
'Especie': ['Leão', 'Tigre', 'Urso Pardo', 'Lobo Cinzento', 'Onça Pintada'],
'tamanho_garras_cm': [6, 8, 10, 4, 7],
'tamanho_focinho_cm': [20, 22, 35, 25, 18]
})
Aqui, já de início, podemos perceber uma coisa: a existência de uma coluna com nome e valores em comum. Esta coluna, Especie, vem a servir de identificador dos DataFrames, uma vez que possui valores que, em princípio, não se repetem na tabela. Desse modo, podemos encarar essa coluna como a chave dos DataFrames que foram criados.
Seguindo a ideia dessa aula, imaginemos a situação de mesclar os dois DataFrames que criamos, com o intuito de juntar todas as características corpóreas de cada espécie registrada nesses dois conjuntos de dados. É perfeitamente possível se valer da função merge() indicando apenas os dois df, conforme exemplo abaixo:
df3 = pd.merge(df1, df2, how='outer')
Existe aí, no entanto, um porém: Ao executarmos esse código, e verificarmos seu resultado, é possível encontrar a coluna Especie repetida, com indicadores atrelados ao nome (algo como Especie_x e Especie_y). Isso, querendo nós ou não, atrapalha muito na hora de fazer quaisquer análises. E o que faremos com isso, então?
Nesse blog, procuramos sempre preconizar o princípio de que existirá uma solução efetiva para os problemas que encontramos na análise de dados usando Python; aqui não será diferente. Para resolvermos essa questão de uma vez por todas, basta complementarmos a linha de código anterior fazendo menção à coluna que as tabelas possuem em comum usando o parâmetro on, conforme exemplo:
df3 = pd.merge(df1, df2, how='outer', on='Especie')
Adicionando valor a esse parâmetro, indicaremos ao pandas que, uma vez encontrado um valor comum de Especie em ambos os conjuntos de dados, a única coisa que é preciso fazer é uma complementação dos dados que já existem, adicionando novas colunas e os valores atrelados a elas. Assim teremos um DataFrame único em df3, sem colunas repetidas, e com todos os dados disponíveis nas duas tabelas, prontas para que possamos tomar quaisquer outras ações posteriores.
Vimos até aqui duas formas muito interessantes de combinar dados oriundos de fontes distintas, concat() e merge(). Com elas, sem a menor sombra de dúvida, você já estará pronto para organizar os vários fragmentos de dados que acaso poderá encontrar ao lidar com arquivos do mundo real. Ainda nos falta discutir um pouco sobre uma outra função que também serve para combinações e mesclas, o join(). Isso faremos em uma próxima oportunidade, de forma mais detalhada e clara.
Um grande abraço, e até o próximo post!
Para ler mais:
What are the 'levels', 'keys', and names arguments for in Pandas' concat function? - Stack Overflow
Python Pandas DataFrame Join, Merge, and Concatenate - Towards Data Science
Practical uses of merge, join and concat - Towards Data Science
Combining Data in pandas With merge(), .join(), and concat() - Real Python



