

Aula 10.1 - Análise e visualização de dados em Python - biblioteca pandas (parte 6)
Como você pode juntar conjuntos de dados em um só

Pense se você já se deparou alguma vez com as seguintes situações:
Os dados que chegam a você para análises estão divididos em duas ou mais tabelas;
Você precisa dividir o conteúdo de uma tabela em dois para poder processar melhor os dados... e depois precisa os juntar outra vez, ou precisa fazer uma análise com uma parte da primeira tabela, e outra parte da segunda;
E nessas duas situações, você não tem ideia do que fazer, além de juntar tudo manualmente, no
Ctrl+C,Ctrl+V, sempre se sujeitando a errar em algo.
Essas situações podem gerar um desperdício de tempo, energia, e dinheiro considerável, sem falar no desespero que pode bater. Então, sendo uma biblioteca completa para análise de dados, o pandas também providencia funções para agregação de diferentes dataframes, sendo soluções fáceis e bastante práticas. A documentação da biblioteca mostra com detalhes as possibilidades para fazer essas combinações, e é esse aspecto do pandas que exploraremos nessa aula.
Então, o que será visto aqui:
Como combinar dataframes com a biblioteca pandas;
Principais funções do pandas para concatenar, unir, e juntar.
Combinar dataframes com o pandas
A documentação do pandas, especialmente no Guia do Usuário, indica que temos, pelo menos, três modos de combinar conjuntos de dados: com concatenação (concat()), união (merge()), e a junção (join()). Para usar essas funções, é preciso levar em consideração duas coisas: o que você quer juntar de duas ou mais tabelas, e onde você quer chegar com isso. Caso isso tenha ficado confuso por agora, não se preocupe, pois à medida em que as funções e suas capacidades forem apresentadas, você poderá já identificar qual a função que vem de encontro ao seu objetivo, e como usá-la para conseguir aquilo que se quer.
Antes de mais nada: carregando os datasets para uso no pandas
Como essa série é baseada na mistura entre partes teóricas e práticas, antes de irmos à parte de apresentação das funções, precisamos carregar os conjuntos de dados com os quais iremos trabalhar aqui. Esses conjuntos estão no repositório da série no GitHub, para que você possa os usar livremente. E como carregaremos mais de um conjunto, faremos aqui uma coisa diferente: em vez de apenas nomear o objeto atribuído ao conjunto de dados apenas como df, usaremos os nomes de cada arquivo .csv disponibilizados. No caso, portanto, os objetos serão nomeados surveys e species, sendo que o processo de nomeação é o mesmo que utilizamos para df.
import pandas as pd #Importação da biblioteca pandas (sempre a primeira coisa a ser feita)
surveys = pd.read_csv("https://github.com/mhalmenschlager/python-biologia/raw/main/archives/surveys.csv") #Carrega o arquivo 'surveys.csv'
species = pd.read_csv("https://github.com/mhalmenschlager/python-biologia/raw/main/archives/species.csv") #Carrega o arquivo 'species.csv'
Isso posto, agora podemos começar a entender como as funções concat(), merge(), e join() funcionam. Para tanto, a aula será dividida em três posts ou partes diferentes:
A primeira parte, que vem a seguir, apresenta a função
concat();A segunda parte discute sobre a função
join();A terceira e última parte será dedicada à função
merge().
Concatenação: função concat()
A função de concatenação é considerada o 'canivete suíço' das funções de combinação de dataframes, podendo operar tanto com linhas, quanto com colunas. A questão aqui é que os dataframes a serem selecionados para a operação serão apenas "colados", seja pelo eixo de suas linhas, ou pelo eixo de suas colunas.
Para entender melhor, façamos o seguinte: a partir do dataframesurveys criado anteriormente, criemos dois outros, com as cinco primeiras entradas e as cinco últimas entradas desse conjunto. Assim:
surveys_primeiras = surveys.head() #Cinco primeiras entradas de 'surveys'
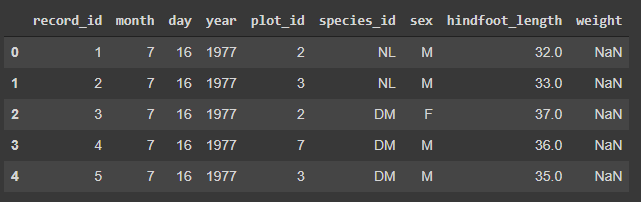
surveys_ultimas = surveys.tail() #Cinco últimas entradas de 'surveys'
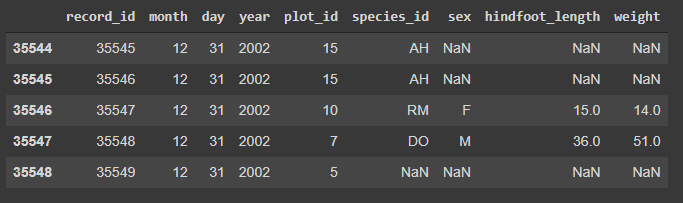
**Um detalhe: **Se você executar os blocos de código que foram até agora aqui expostos, poderá perceber uma coisa: ao criarmos os novos objetos, a tabela
surveys_ultimasmantém a indexação da tabela da qual se originou. Caso queiramos que haja uma indexação nova, há uma função para isso:reset.index(). Usamos ela da seguinte forma:surveys_ultimas = surveys_ultimas.reset_index(drop=True) #Reorganiza o índice de 'surveys_ultimas', trocando o índice antigo de 'surveys' para um novo.Esta função será mencionada outras vezes nessa aula, uma vez que ela será importante para que possamos fazer o processo de concatenação de forma correta em um dado momento.
Tendo esses novos objetos em mãos, podemos fazer a operação de concatenação, seja ela vertical (colados pelo eixo das colunas), ou horizontal (colados pelo eixo das linhas), usando a função concat().
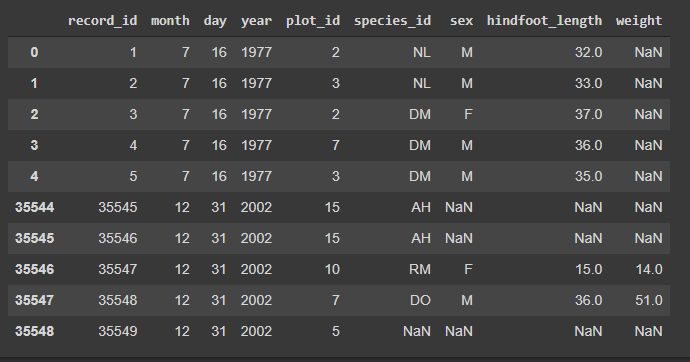
vertical = pd.concat([surveys_primeiras, surveys_ultimas], axis=0) #Concatenação vertical
horizontal = pd.concat([surveys_primeiras, surveys_ultimas], axis=1) #Concatenação horizontal
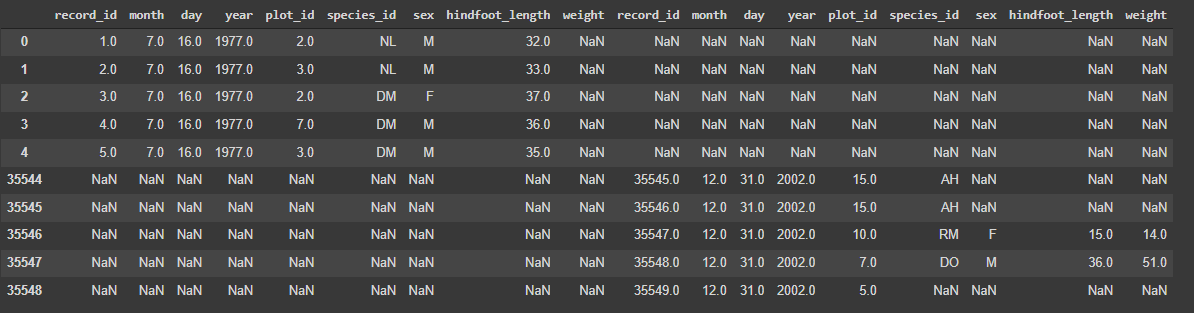
Repare que, quando a função concat()é chamada, há um parâmetro que indica por qual eixo queremos fazer a concatenação, o axis. Então, para que a operação corra bem, lembre-se sempre de que, para fazer a operação vertical, o axis possui valor 0; para a horizontal, valor 1. Ainda, precisamos sempre reparar se as coisas estão fazendo sentido: ao fazermos a concatenação horizontal, os dados contidos nas linhas a serem coladas precisam estar relacionados de alguma forma. Na concatenação vertical, é imperativo verificar se as colunas possuem as mesmas características, i.e., o mesmo nome e o mesmo tipo de dado.
Um detalhe: Quando fazemos a concatenação vertical, podemos passar por um pequeno problema: os índices das linhas não tem continuidade, pulando do índice 4 para o 35544 de uma vez só. Isso acontece porque colamos linhas e colunas de dataframes com seus próprios índices. Um modo de contornar o problema é utilizar a função
reset_index()(olha ela aqui de novo!) para que o índice seja reorganizado. Assim:vertical = vertical.reset_index() #Reseta o índice
Perceba que a indexação agora aparece organizada.
Outro detalhe: Não parece que a concatenação horizontal ficou parecendo uma bagunça, cheia de
NaN? Isso aconteceu por um motivo simples: quando as tabelas são colocadas lado a lado, as identificações das colunas podem se repetir, e as linhas acabam por ganhar 'extensões'; como não há dados nessas novas células, elas aparecem como dados nulos. Para resolver essa 'zona', podemos utilizar oreset_index()mais uma vez. Nesse caso, podemos criar um novo objeto com o índice resetado, e fazermos a concatenação outra vez. Assim:surveys_ultimas2 = surveys_ultimas.reset_index(drop=True) #Cria um novo objeto, 'surveys_ultimas2', com o índice resetado horizontal_2 = pd.concat([surveys_primeiras, surveys_ultimas2], axis=1) #Faz concatenação horizontal, com as duas tabelas tendo mesmo índice
Agora sim, temos uma concatenação horizontal mais bem organizada do que a anterior.
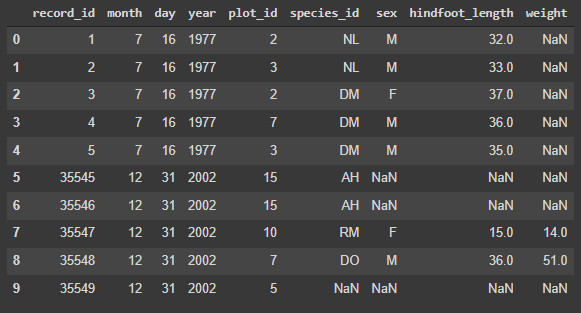

A função concat() é uma excelente função para a união de dois ou mais dataframes baseando-se em suas indexações, uma vez que pode trabalhar tanto com o eixo das linhas, quanto o das colunas, se transformando no 'canivete suíço' das funções que usam o índice como base. O que foi apresentado aqui é uma parte mais básica da função, com a qual você já pode sair praticando com outras bases de dados; concat() possui mais detalhes em seus argumentos, fazendo com que valha a pena analisar a documentação e outras referências para ter noção do poder dessa função no que se refere a juntar conjuntos de dados.
Aproveite para praticar a função concat()e nos vemos nas próximas partes, onde discutiremos mais sobre merge(), outra formas de juntar conjuntos de dados.
Um grande abraço e até o próximo post!
Para ler mais:




